











前回記事でAI(人工知能)のこれまでを見てきました。
今回はブレイクスルーのきっかけとなったディープラーニングについて、深掘りしていきたいと思います。
機械学習、表現学習、ディープラーニングといった重要用語の整理ですね。
目次(クリックで飛びます)
ディープラーニングは機械学習の進化系
先の記事でも述べた通り、ディープラーニングの方法論自体はニューラルネットワークの模倣であり、真新しい技術ではありません。
(出典:NRI)
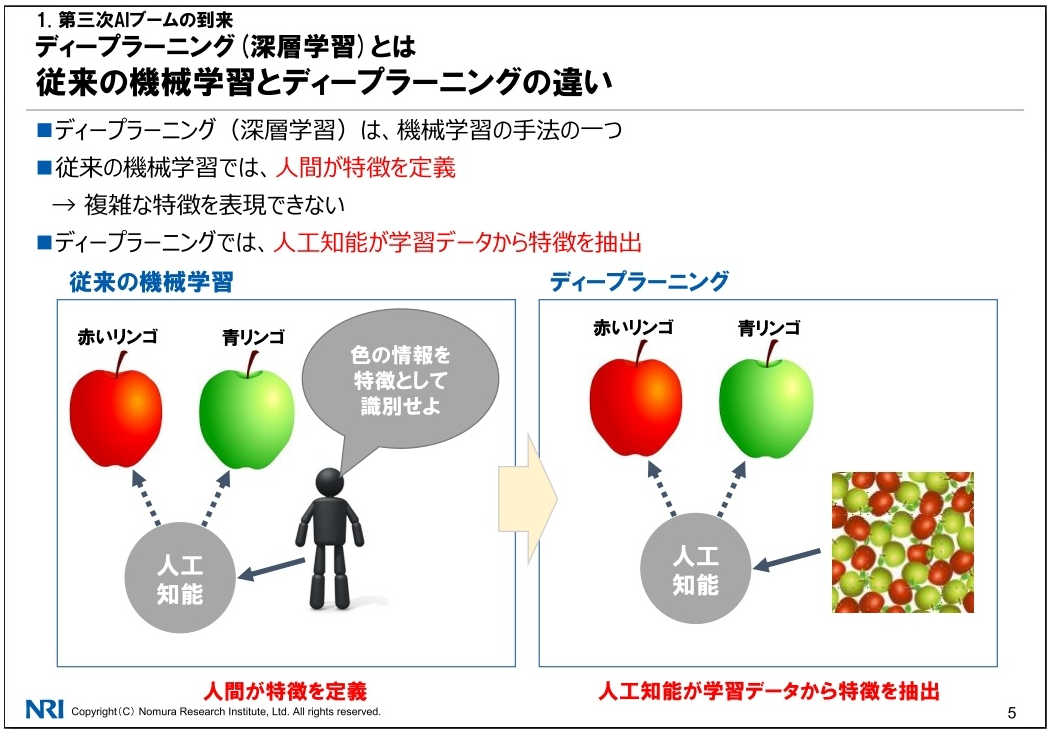
従来の機械学習は人間が分け方を教える
従来の機械学習とは、ある写真を見て、それが猫なのか犬なのかを区別していく学習のことを指しました。
区別するための基準=特徴量を教えるのは人間です。
ベイズ推定(ナイーブベイズ法)
統計学を学んでいると確実に出てくるベイズ推定は、ある事象についての結果を確率的に推論する理論です。
一般的な推定では真のモデルがあって、次の結果は真のモデルに当てはめた解の一つであるというもの。具体的には……コイントスで表が出る確率は真のモデル「50%」という絶対値があり、回数を重ねて行くほど結果の分布はこの確率に近づいていくと考えられます。逆に言えば、真のモデルを見つけ出すにはある程度の試行回数が必要です。
ところがベイズ推定では、事前に適当な確率を置いてしまいます。そして、結果が出る度に事前の確率を更新していくことで、正しい確率に近づけていこうというアプローチです。
……という荒っぽすぎる前提の上で、ベイズ推定を活かした機械学習の例としては迷惑メールが挙げられます。
これは機械がメールの文面を見て、「ある単語が入っていると迷惑メールの確率が何%ある」と判断し、基準以上になると迷惑メールとして仕分ける仕組みです。ベイズ推定によって、迷惑メールに振り分けたメールを利用者が削除すれば(つまり人が教えれば)、「結果を正しいもの」と機械が学習し、確率が更新されていきます。
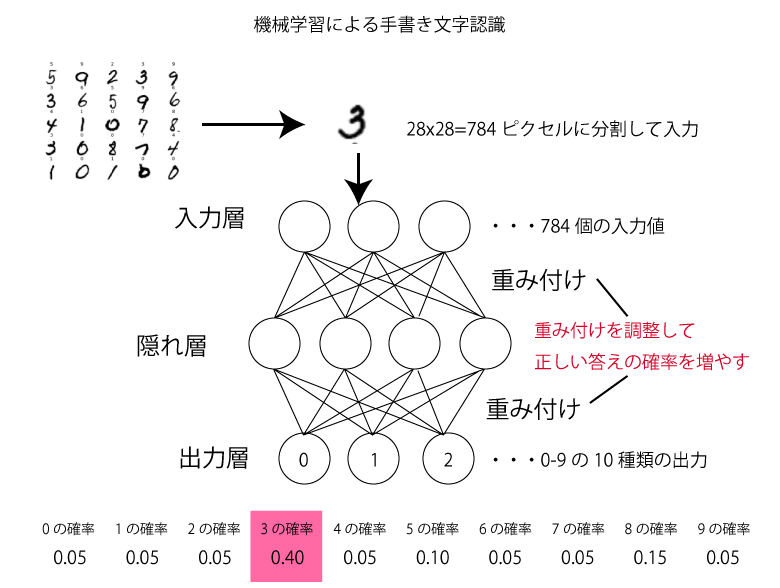
ニューラルネットワーク
ニューラルネットワークとは、人間の脳の仕組みを模して、機械と電気信号で実現させようというものです。
下の図が大変分かりやすいのですが、要は細かく分解してひたすらトライ・アンド・エラーを繰り返し、正解不正解の境界を分ける重み付けの調整をするわけです。
(出典:IoTNEWS)
しかし、先ほども述べたように、重み付けの基準=特徴量を教えるのは人間です。中間層(隠れ層)が一つしかない時代のニューラルネットワークでは、複雑な判別はもちろん、特徴量の抽出は不可能でした。
ディープラーニングは機械が分け方そのものを学習する
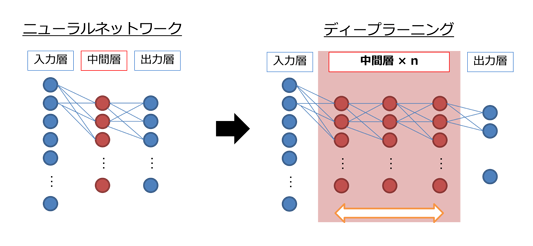
対して、ディープラーニングでは人間が教えることなく、機械自身が特徴量を抽出します。ここがポイント。
ディープラーニングはニューラルネットワーク・アルゴリズムの発展形で、以下のように中間層が増えています。中間層が多くなるほど、簡単な特徴量を組み合わせて、より高いレベルの特徴量を表現出来るようになります。
仕組み自体は特に新しくないのですが、近年の計算パワー向上やビッグデータ解析技術の進展によって実用可能になりました。
(出典:MarkeZine)
これまでは特徴量の抽出という領域は人間にしか出来ないものとされてきましたが、機械でも可能となったことで、映像や音声の識別が出来るようになります。これはデータさえあれば機械が全部学習していってくれるということですね。
Googleが機械にYoutubeで猫の動画を見せ続けると、機械は猫を画像認識出来るようになりました。あるいは、手書きの文字から書いた人を判別出来るようになりました。例えば犬や猫、老若男女有機物無機物どんなものでも――人間には識別出来ないようなものでも――機械は特徴量を発見し、識別するようになるでしょう。
すると、あらゆる事象を膨大なデータから分析・学習し、問題解決(サポート)・情報抽出・レコメンド等のビジネスへ大きく広がっていくものと予想されます。
種類やアルゴリズムについて
個々の詳しい説明は無理でした。
- 畳み込みニューラルネットワーク
- 再帰性ニューラルネットワーク
- 制限付きボルツマンマシン(RBM)
- ディープビリーフネット(DBN)
- Stackedオートエンコーダ
アルゴリズムはこの辺りのサイト様で詳しいのでご参考までに。
ディープラーニングの現在についての注意点
絶賛してきましたが、ニ点注意すべき点が。
ディープラーニングは今のところ「認識」のみ
ディープラーニングで機械が出来るのは、あるデータの「認識」だけです。その先の推論・判断といった領域はまだ未開拓の状態ですので、「認識することそのものに意義があるビジネス」が、ディープラーニングを最初に適用させるビジネスになるでしょう。
同じ話で、例えばある商品がヒットする可能性が高いと機械が予測したとして、「なぜ」その商品がヒットするのか、理屈は出せないということです。過去のヒット作を統計的に分析した結果、同じ傾向にある商品=ヒットすると予測している、というだけだからです。
ただし、商品がヒットする過程には数々の要因があるでしょう。それこそバタフライエフェクト的に無数の変数が互いに干渉しあってヒットという結果を生んでいるので、それを説明するというのもナンセンスです。私個人の考えとしては、どれだけマシンパワーが上がったところで、成功要素を完全に分解することは不可能だと思っています。だって機械の弾き出した結果によって現実が変わり、未来が変わりますからね(再帰性とか言う)。
ビッグデータの限界については、以下に記事を書いていますので、合わせてどうぞ。

もちろん、将来的には推論・判断も含めて出来ることがAIの完成形なんでしょうけどね。
ディープラーニングの認識精度は8割くらい?
まだ100%の精度は実現出来ていません。まあ、個人的には8割当たれば十分使えると思いますけどね。人間だって間違いだらけですし、そもそもすべての事象が完全に分けられる分界点があるとも思えません。
FXでEAを組んだ人は分かると思いますが、極度の適応化はカーブフィッティングになり、現実では使い物にならないことがままありますので、8割で活かせるビジネス――上と同じですが、「精度は低くても」認識出来ることそのものに意義がある領域――を探すべきでしょう。
……となると、自動化された予測モデリングが中心になるのか。
ディープラーニングとデータマイニングの違い
データマイニングは未知のパターンを発見する統計手法ですね。逆にディープラーニングは上の話から、既知のパターンを再発掘する手法と言えるでしょうか。
もうちょっと書きたかったのですが、疲れたのでここまでにします。銘柄分析からどんどん脇道に逸れている気がしないでもないですが、せめてこのくらいの概略程度はおさえておきたいんですよね。
ということで、次回以降は、AI全体を含めて実際のビジネスにおける活用シーン、市場規模やロードマップを見ていきたいと思います。

他のIT系テーマについて以下でまとめております。よろしければ合わせてお読みいただけるとうれしいです。
